18.12.2020 Linked Data
Aktuelle Datenmodelle für Metadaten
Nachdem wir im Kurs bereits viele stark etablierte Metadatenstandards kennengelernt und auch damit gearbeitet haben, wurden wir heute in zwei neuere Entwicklungen eingeführt: BIBFRAME und Records in Context (RiC). Diese beiden gelten in der Bibliotheks- bzw. Archivwelt zwar auch bereits als etabliert, so richtig angekommen sind sie jedoch noch nicht überall (institutionell aber auch in Software). Trotzdem sollten sie einem vertraut sein, da sie in Zukunft an Relevanz gewinnen dürften.
BIBFRAME
BIBFRAME bezeichnet einerseits die Initiative “Bibliographic Framework” der Library of Congress, andererseits das Produkt selbst – das Metadatenmodell –, welches aus ihr entstanden ist. Seit dem Start der Initiative im Jahr 2012 liegt nun seit 2016 die aktuelle Version BIBFRAME 2.0 vor. Ziel war es, einen modernen Nachfolger von MARC21 (und MODS) zu entwickeln, der kompatibel mit neueren technischen Entwicklungen ist. In dem Rahmenwerk BIBFRAME können bibliographische Daten mithilfe der Technologien von Linked Data und Semantic Web erfasst, gespeichert, transportiert und bereitsgetellt werden. Ein weiterer Auslöser für diese Bestrebungen war die Einführung von RDA (Resource Description and Access) als neues Regelwerk für die Katalogisierung in Bibliotheken. BIBFRAME basiert neben RDA auch auf Functional Requirements for Bibliographic Records (FRBR) als Regelwerk, wenn auch diese Konzepte in vereinfachter Form und somit nicht vollständig übernommen werden (was z.T. kritisiert wird).
Im Gegensaz zu MARC21 folgt BIBFRAME (wie auch LIDO) den Prinzipien von Linked Data:
- Es werden einheitliche Vokabulare verwendet
- Alles, was in diesem Fomat beschrieben ist, ist eindeutig über eine URI identifizierbar und somit auch adressierbar
- Die Entitäten, die beschrieben werden, sind wiederverwertbar. Bspw. wird eine bestimmte Autorin als eigenständige Entität einmalig erfasst und kann dann in unterschiedlichen Datensätzen mit den Publikationen verknüpft werden. Dieses Prinzip unterscheidet sich deutlich von MARC21, bei dem jede/r Autor/in in jedem Datensatz wiederholt werden muss.
BIBFRAME besteht aus zwei Teilen – dem Datenmodell und dem Vokabular:
- BIBFRAME Model: Hier werden 3 verschiedene Ebenen bezeichnet (Work, Instance, Item), die an FRBR angelehnt sind. Work meint dabei das Werk als geistige Schöpfung; Instance die entsprechende Ausgabe dieses Werks; Item das konkrete Exemplar, das z.B. in einer bestimmten Bibliothek vorhanden und ausleihbar ist. Diese Trennung der Ebenen ist neu, da in MARC21 jeweils im gleichen Datensatz alle 3 Ebenen beschrieben werden. Um diese Ebenen beschreiben zu können, sieht das Modell u.a. die Entitäten Agent (an der Entstehung eines Werks beteiligte Personen/Körperschaften), Subject (Themen, Personen, Ereignisse etc., die im Werk behandelt werden) und Event (Inhalt des Werks, z.B. ein Theaterstück oder ein Interview, das im Werk wiedergegeben wird). Diese Entitäten treffen dabei nicht auf jedes Werk zu.
- BIBFRAME Vocabulary: Dient der Beschreibng dieser 3 Ebenen und der Entitäten. Das Vokabular definiert Konzepte und teilt diesen Eigenschaften zu. Bspw. ist darin das Konzept “Autor/in” definiert, welches Vorname, Nachname etc. als Eigenschaften enthält. Das Vokabular dient hauptsächlich dazu, dass alle dieselben Begriffe verwenden und ein gleiches Verständnis von z.B. dem Konzept “Autor/in” haben. Die Vocabulary-Ontologie beinhaltet Beschreibungsklassen (Class, z.B. Autor/in), welche wiederum spezifische Eigenschaften (Property, z.B. Geburtsdatum) vorweisen. In MARC21 wird dieses Konzept mit Fields und Subfields abgebildet.
Unterscheidung von MARC21 und BIBFRAME auf den Punkt gebracht:
- In MARC21 wird ein Objekt in einem Datensatz umfassend beschrieben, sodass kein weiteres Kontextwissen vorhanden oder andere Datensätze hinzugezogen werden müssen, um dieses zu verstehen. Somit steht jeder Datensatz für sich allein. Für die Abbildung in einem klassischen Katalog ist dies ausreichend.
- In BIBFRAME erfolgt die Beschreibung eines Objekts durch die Zusammenführung unterschiedlicher Datensätze. Datensätze zu einem Ort, einer Person, eines Werks etc. stehen in Beziehung zueinander und ergänzen sich somit. Informationen zu ein und derselben Entität werden also nicht mehrfach abgelegt. Dieses Modell erlaubt es, viel mehr Informationen herauszulesen, als es im MARC21-Modell der Fall ist.
Wie ein Datensatz in BIBFRAME aussieht? Hier eine Gegenüberstellung zu MARCXML:
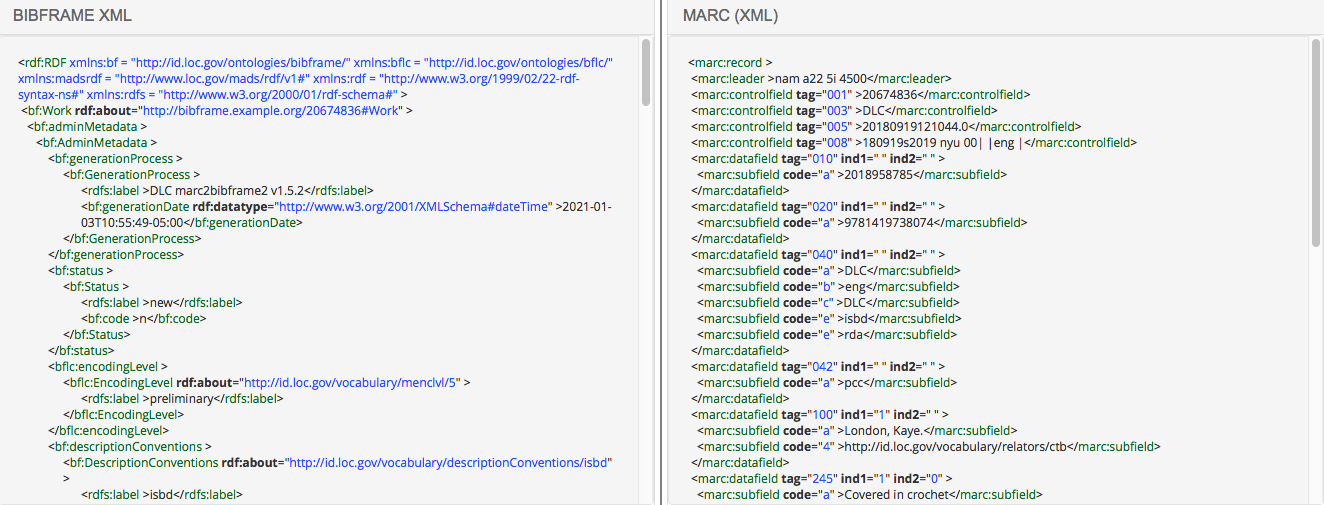
Records in Context (RiC)
RiC wurde in diesem Blog bereits im Eintrag zum 09.10.2020 kurz vorgestellt sowie die Projektgruppe ENSEMEN erwähnt, die an einer schweizerischen Ausprägung dieses Standards arbeitet. Ähnlich wie bei BIBFRAME resultieren aus RiC auch zwei Produkte: Das Conceptual Model for archival description (RiC-CM) sowie die Ontology for archival description (RiC-O). Was gibt es bereits für Tools?
- docuteam arbeitet an Prototypen für RiC-konforme Erschliessungs- und Katalogisiersoftware: https://ica-egad.github.io/RiC-O/projects-and-tools.html
- den RiC-O Converter – eine Open-Source-Software für die Konvertierung von RDF Datensets in RiC-O v0.1
Aus einem Artikel von David Gniffke, der die Neuerungen und Vorzüge von RiC sehr gut zusammenfasst, nehme ich folgendes mit:
- Es gibt einen Kodex ethischer Grundsätze für Archivar/innen des Internationalen Archivrats (ICA), worin es heisst: „Archivarinnen und Archivare haben sich für die weitest mögliche Benutzung von Archivalien einzusetzen“
- Auch wenn RiC auf den bestehenden Standards im Archivbereich aufbaut und mit ihnen kompatibel ist, wird es im Zuge der Umstellung notwendig sein, Bestände neu zu erschliessen, um diese insbesondere maschinenlesbar zu machen – dabei können algorithmusgestützte Verfahren hilfreich sein
- Der suchende Nutzer wird zum entdeckenden Nutzer: Suchergebnisse werden um ähnliche Treffer ergänzt, zudem können Anfragen viel exakter gestellt werden (wobei jedoch Kenntnisse in SPARQL Voraussetzung sind). Interessant finde ich hierbei seinen Vorschlag, dass Archivar/innen zukünftig die Nutzenden in SPARQL unterrichten – das stelle ich mir irgendwie schwierig vor, zumal ich diese Abfragesprache als nicht trivial kennengelernt habe und sogar als IW-Studentin Mühe habe damit.
Quellen: BIBFRAME, Gegenüberstellung BIBFRAME/MARCXML, Records in Context, Artikel von David Gniffke zu RiC, BAIN-Skript 7