09.10.2020 Funktion und Aufbau von Archivsystemen (1/2)
Metadatenstandards in Archiven – ISAD(G) und EAD
ISAD(G)
Ein wichtiger (internationaler) Standard zur Erschliessung von Archivgut bildet ISAD(G) (International Standard Archival Description (General), der 1994 eingeführt wurde und seit der Revision im Jahr 2000 in der zweiten, heute aktuellen Fassung vorliegt. ISAD(G) funktioniert anders als klassische, medienzentrierte Standards (wie wir es von Bibliotheken kennen). Man beginnt nicht damit, das Medium zu beschreiben, sondern jene Person, welche das zu beschreibende Konvolut erstellt hat (Aktenbildner/in). Man erschliesst also nach dem Provenienzprinzip (Herkunft). Warum ist das so? Archivbestände sind meistens unikal, sodass man den ganzen Kontext, die Bestandsgeschichte, umfassend dokumentieren möchte. Das Aufbauprinzip von ISAD(G) ist ein Stufenmodell, d.h. dass Erschliessungsinformation, welche bereits auf höherer Ebene erfasst wird, nicht auf den nachgeordneten Ebenen wiederholt wird (Vererbungsgrundsatz). Die Stufenverzeichnung ist ein Versuch, der Vereinzelung/Individualisierung von Archivguteinheiten entgegenzuwirken. Die Grenzen von ISAD(G):
- Indem gewisse Information, welche bereits auf höherer Stufe erfasst wurde, für nachfolgende Stufen nicht wiederholt wird, sind einzelne Datensätze u. U. nicht genügend umfassend beschrieben. Es muss der grössere Kontext betrachtet werden. Dies zeigt sich auch in der Vergabe von Titeln (z.B. “Protokoll”).
- Aus dem obgenannten Grund ist es auch schwierig, die Datensätze in einem Discovery-System auszugeben – die übergeordnete Stufe muss immer mitabgebildet werden.
- Im Standard sind keine Vorgaben zur Digitalisierung oder zur digitalen Langzeitarchivierung enthalten.
- Die Tektonik ist eindimensional, somit sind keine Mehrfachzuordnungen möglich.
ISAD(G) enthält 26 Verzeichniselemente in 7 Informationsbereichen:
- Identifikation
- Kontext
- Inhalt und innere Ordnung
- Zugangs- und Benutzungsbedingungen
- Sachverwandte Unterlagen
- Anmerkungen
- Kontrolle
Wichtig sind dabei insbesondere 6 Pflichtfelder:
- Signatur
- Titel
- Provenienz
- Entstehungszeitraum
- Umfang
- Verzeichnungsstufe
Normdaten mit ISAD(G)
Um Aktenbildner/innen beschreiben zu können, existiert der (internationale) Standard ISAAR(CPF) (International Standard Archival Authority Record for Corporate Bodies, Persons, and Famlies). Die 2004 überarbeitete Version ersetzt die im Jahr 1995 publizierte erste Fassung. In der Praxis findet dieser Standard jedoch kaum Anwendung aufgrund des zusätzlichen Erschliessungsaufwands, welcher aufgewendet werden muss. Um Personenangaben mit Normdateien zu verknüpfen, wird in Archiven nicht selten die GND genutzt. Dies ist bspw. in den Archiven der ETH-Bibliothek oder auch in der Abteilung ‘Handschriften und alte Drucke’ der Universität Basel der Fall, wobei hier die Bibliothekszugehörigkeit eine wesentliche Rolle spielt. Aber auch im Schweizerischen Kunstarchiv von SIK-ISEA, wo ich arbeite, werden Aktenbildner/innen im künftigen Archivsystem ANTON mit deren GND-Eintrag verknüpft.
Aktuell wird an einem neuen Standard gearbeitet, welcher die bereits vorhandenen harmonisieren und weiterentwickeln soll. RiC (Records in Contexts) beruht auf Linked-Date-Prinzipien und soll u. a. die Darstellung von pluralen sowie parallelen Beziehungen zwischen Elementen ermöglichen (siehe dazu auch den Blogeintrag zum 18.12.2020). Die Projektgruppe ENSEMEN entwickelt derzeit eine Schweizer Umsetzung dieses Standards und formuliert die folgenden Ziele:
- Grundlagen für die Erhebung und das Management von Meta- und Primärdaten, die einen maschinenlesbaren, automatisierbaren Austausch dieser über die Systemgrenzen hinweg ermöglichen werden.
- Grundlagen zur Definition eines Information Package (IP) unter Berücksichtigung von aktuellen Arbeiten.
Übung: Archivkataloge
Suche nach Einstein im Online Archivkatalog des Staatsarchivs BS (Software: scopeArchiv)
Suche nach Einstein Ehrat im Hochschularchiv ETH Zürich (Software: CMI STAR)
- Welche Informationen enthält die Trefferliste? Titel, Zeitraum, Signatur, Archivplan, Benutzbarkeit, Relevanz.
- Welche Verzeichnungsstufen sind vertreten? Alle. Im ETH-Katalog kann zusätzlich danach gefiltert werden.
- Sind die ISAD(G)-Informationsbereiche erkennbar? Im StABS-Katalog sind die Rubriken nach ihnen benannt, was hilfreich ist zur Orientierung. Im ETH-Katalog sind sie nicht sofort erkennbar. Gewisse sind nur auf einer bestimmten Stufe vorhanden.
- Decken sich die grundlegenden Informationen oder gibt es bemerkenswerte Unterschiede? Ja. Der StABS-Katalog ist m. E. übersichtlicher gestaltet.
- Worin liegen die zentralen Unterschiede zu einem Bibliothekskatalog? Es reicht nicht aus, einen Datensatz anzuschauen. Es muss immer auch geprüft werden, ob er Teil eines grösseren Konvoluts ist oder es noch höhere Stufen gibt, um die umfassenden Informationen dazu zu erhalten.
EAD
EAD (Encoded Archival Description) ist ein XML-Standard, der in verschiedenen Versionen vorliegt (EAD2002 und EAD3 seit August 2015). Es gibt Anwendungsprofile, die näher spezifizieren, welche Werte erlaubt sind. Anwendungsfälle sind z.B. Archives Portal Europa, Archivportal-D, Kalliope. Gute Einführung: Nicolas Moretto (2014): EAD und digitalisiertes Archivgut. Präsentation auf dem DINI AG KIM Workshop 2014 in Mannheim.
Aktuelle Entwicklungen
- Umstieg von ISAD(G) auf RiC ist mit hohem Aufwand verbunden und bedingt vermutlich einen Softwarewechsel.
- Die Generierung von Volltexten nimmt zu, u. a. durch Optical Character Recognition (OCR) – auch für Handschriften. Durch Named Entity Recognition (Identifikation und Klassifikation von Eigennamen) wird die automatische Anreicherung von Volltexten ermöglicht.
- In Wikidata werden Online-Findmittel über Property Archives at verzeichnet. Beispiel Albert Einstein in Wikidata: Es werden alle Plattformen aufgeführt, welche auf die hier im Datensatz versammelten Daten zurückgreifen. Auch hat die ETH dort die Information hinterlegt, dass sie einen Nachlass von Einstein besitzt. Würden diesem Beispiel viele weitere Institutionen folgen, wäre Vernetzung möglich sowie Visualisierungen.
- In der Schweiz gibt es eine Vernetzungsinitiative Metagrid (Bereitstellung von Normdaten) und weitere Dienste von histHub, einer Forschungsplattform für die Historischen Wissenschaften.
ArchivesSpace
ArchivesSpace ist ein Open-Source-Archivinformationssystem. Institutionell verankert ist es bei Lyrasis, einem internationalen “non-profit” Bibliotheksnetzwerk (vorrangig USA). Daneben gibt es zwei weitere Unternehmen, die professionellen Support anbieten (ein Zeichen für nachhaltige Software!). Es gibt 400 zahlende Mitglieder, woraus fast 5 Vollzeitstellen bezahlt werden. Die Software basiert auf den Metadaten-Standards DACS, ISAD(G) und ISAAR(CPF) und unterstützt Import/Export in die Formate EAD, MARCXML und METS. Verwendet wird das System v. a. in den USA, weshalb es auch Vorgaben enthalten kann, die für Europa weniger zutreffend sind. In der Schweiz scheint das System bisher nicht im Einsatz zu sein:
Ein Blick auf ArchivesSpace bei Open Hub gibt preis, dass die Aktivität als auch die Anzahl Mitwirkenden (Community) in den letzten 12 Monaten stark abgenommen hat. In diesem Zeitraum gab es lediglich 23 Commits von 7 Mitwirkenden. Ob diese Zahlen grundsätzlich angemessen sind für eine Software dieser Komplexität kann ich nicht beurteilen, dass die Zahlen jedoch sinkend sind, ist vermutlich kein gutes Zeichen. Koha hatte im Vergleich dazu 9400 Commits in den vergangenen 12 Monaten.

Installation von ArchivesSpace
Die Installation verlief problemlos. Grundsätzlich gilt, dass man jedes System in einer eigenen Umgebung installieren sollte, da Versions- oder Ressourcenkonflikte entstehen können. Erstere können auftauchen, wenn unterschiedliche Versionen derselben Programmiersprache oder Datenbank benötigt werden. Bezüglich Ressourcen ist v. a. der Arbeitsspeicher betroffen. Um Ressourcen zu sparen und den Wartungsaufwand zu reduzieren, werden virtuelle Maschinen oder Container eingesetzt. In unserem Fall haben wir Glück; Koha und ArchivesSpace vertragen sich glücklicherweise ziemlich gut. Die Software wird im Terminal unter archivesspace/archivesspace.sh gestartet und ist nur so lange verfügbar, wie der Prozess im Terminal läuft.
Übung: Datensätze erstellen
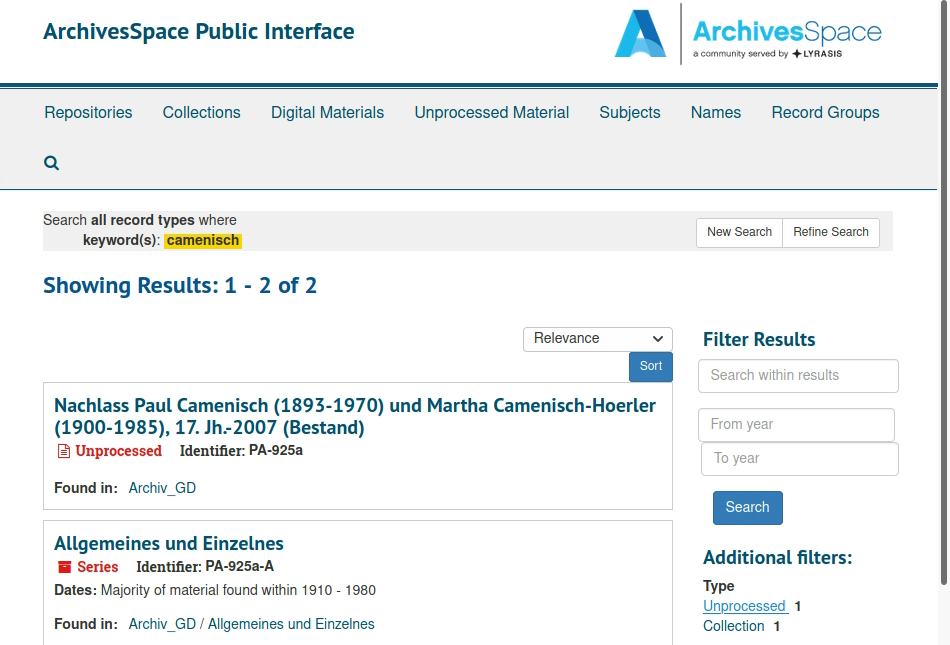
Im Rahmen einer Übung haben wir Datensätze in ArchivesSpace erstellt. Starten musste man hierbei mit einer Accession (Provenienzprinzip!); mit diesem Eintrag zur Erwerbung können dann weitere Datensätze zur Beschreibung der Dokumente (Resources) verknüpft werden. Die Angaben aus dem Erwerbungsdatensatz werden automatisch in die Beschreibung der Ressourcen übernommen (Vererbungsgrundsatz). Meine Gruppe hat sich entschieden, hierfür einen im Staatsarchiv Basel-Stadt existierenden Nachlass als Vorlage zu nehmen: PA 925a, Nachlass Paul Camenisch (1893-1970) und Martha Camenisch-Hoerler (1900-1985). Wir sind dabei intuitiv vorgegangen und haben die Werte Feld für Feld in der Vorlage des StaBS gesucht und übertragen. Schwierigkeiten hatten wir einerseits wegen der Sprache; nicht immer konnten wir einen Begriff sofort ins Deutsche übersetzen. Geholfen hat uns dabei die Infobox, die in ArchivesSpace erscheint, sobald man sich mit der Maus über einem Feld befindet. Dennoch kam es ab und zu vor, dass wir bestimmte Werte nach Voranschreiten im Formular neu platziert haben, wenn wir auf passendere Felder gestossen sind. Es wäre sicherlich ein besseres Vorgehen gewesen, wenn man sich vorher den Feldkatalog als Ganzes angeschaut hätte, um sich einen Überblick zu verschaffen. Trotzdem konnten wir zwei Datensätze – auf Stufe Bestand und Serie – erstellen und die wichtigsten Angaben aus der Vorlage einsetzen. Sie sind in der öffentlichen Ansicht unter http://localhost:8081 einsehbar:
Nachtrag: Als in der nachfolgenden BAIN-Einheit die Begrifflichkeiten in ArchivesSpace geklärt wurden, wurde mir klar, dass auch ich meine Beispieldatensätze nicht ganz korrekt erstellt hatte. Ich habe nämlich Accession mit Bestand sowie Resource mit den Verzeichnisstufen (z.B. Serie) gleichgesetzt. Beim nächsten Mal weiss ich es besser oder werde gar zunächst das hilfreiche User Manual der NYU konsultieren:
- Accession: Dokumentation der Erwerbung, wegen vertraulichen Angaben oft nicht öffentlich (wir hatten das gleich auf “public” gesetzt)
- Resource: Zentraler Nachweis auf der obersten Ebene der Verzeichnungsstufen, zum Beispiel zu einem Nachlass (kann aber auch direkt zum Objekt sein, wenn die Resource nur eine Verzeichnungsstufe hat)
- Archival Object: Nachweis von Objekten auf weiteren Verzeichnungsstufen (Bestand/Fonds, Serie/Series, Akte/File, Einzelstück/Item). Sie werden als “Add Child” an vorhandene Resources gehängt.
Quellen: ISAD(G), RiC, ENSEMEN, ArchivesSpace bei Open Hub, BAIN-Skript 3