20.11.2020 Anreicherung von Daten mit lobid-gnd in OpenRefine
Zusatzaufgabe
Aufgabe 1: Reichern Sie die Autorennamen in den DOAJ-Daten um zusätzliche Informationen (z.B. GND-Nummer und Geburtsjahr) aus lobid-gnd an.
Material: Anleitung lobig-gnd, DOAJ-Daten in OpenRefine
Um die Autoren-Daten mit Daten aus der GND anreichern zu können, müssen zunächst die Personen (Autoren) selbst mit der GND abgeglichen werden:
- Ich splitte zunächste die Spalte mit den Autorennamen:
Authors>Edit cells>Split multi-valued cells - Nun füge ich den GND-Reconcile-Service hinzu: Spalte
Authors>Reconcile>Start reconciling>Add Standard Service. Hier gebe ichhttps://lobid.org/gnd/reconcileein. - Nachdem der neue Service hinzugefügt wurde, klicke ich ihn an und danach auf
Individualisierte Person– wir machen den Abgleich ja für Personendaten. Anschliessend klicke ichStart reconciling. - Kaffepause – Prozess dauert eine Weile.
-
Nachdem der Abgleich erfolgt ist, kann man erkennen, dass nicht alle Autoren gematchet wurden, also nicht alle Personen einen GND-Eintrag haben bzw. dieser nicht eindeutig zugeordnet werden konnte. Es werden Optionen vorgeschlagen, über die man mit der Maus fahren kann, um weitere Informationen zu erhalten. Alternativ kann man in eine Zelle klicken und auf
Search for match– auch hier erscheint eine Liste mit vorgeschlagenene GND-Einträgen. Auf diese Weise kann man manuell Matches erstellen. Ich entscheide mich gegen diese Arbeit, da es zu viel Aufwand bereiten würde, die Autoren und Publikationen zu recherchieren. Auch muss hier angemerkt werden, dass der Abgleich mit der GND generell heikel ist; auch bei eindeutigen Matches muss es nicht zwingend die korrekte Person sein. Um ganz sicher zu sein, müsste man auf eine Autor/innen-Identifikationsnummer zurückgreifen, wie wir es von Orcid kennen.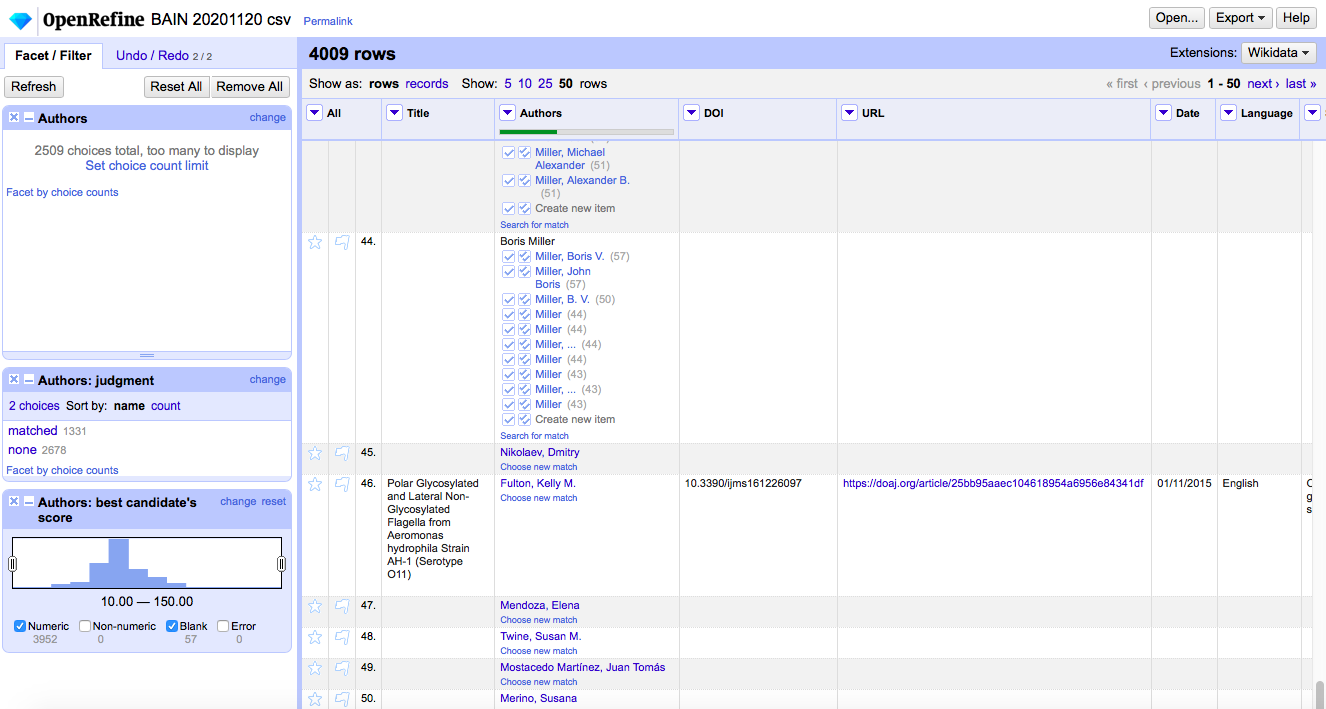
Nachdem die Autoren mit ihren GND-Einträgen abgeglichen wurden, kann man diese nun mit weiteren Daten aus der GND anreichern: - Spalte
Authors>Edit column>Add columns from reconciled values. Es werden nun in einer Liste Eigenschaften vorgeschlagen, die man aus der GND anreichern könnte. Ich wähle GND-Nummer, Geburtsdatum, Geburtsort. Im Feld rechts erscheint nun eine Preview der angereicherten Daten, die dann in neuen Spalten ausgegeben werden. Diesen Schritt musste ich zwei Mal machen, da mir beim ersten Versuch ein kleiner Fehler unterlaufen ist: Nachdem ich Geburtsort, GND-Nummer, Geburtsdatum ausgewählt habe, hat es in der Preview nichts angezeigt. Ich bin davon ausgegangen, dass die in dr Preview angezeigten Zeilen zufällig alle keinen Match hatten. Als ich dann aber die Anreicherung bestätigt hatte, konnte ich auch keine zusätzlichen Spalten im Dokument sehen. Da habe ich bemerkt, dass die facet “unmatched” angeklickt war. Ich wollte also die ungematchten Autoren mit GND-Daten anreichern, was natürlich nicht geht. Ich habe das facet also gelöscht und den Schritt wiederholt. Im Screenshot sieht man Beispieldaten mit den angereicherten Daten: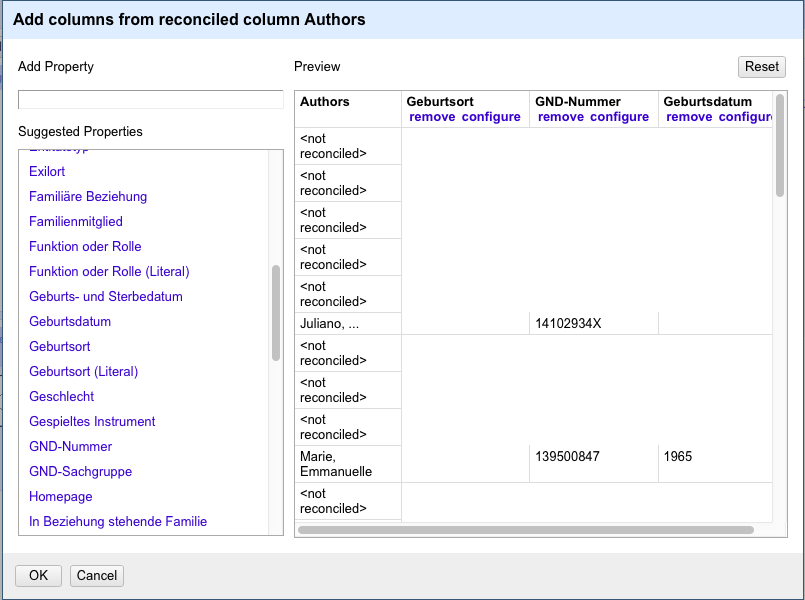
- Nach dem Bestätigen der Anreicherung heisst es nochmals warten (Prozess dauert einen Moment).
- Fertig. Im Ergebnis haben wir 3 neue Spalten (Geburtsort, GND-Nummer, Geburtsdatum), die wir direkt von der GND bezogen haben:
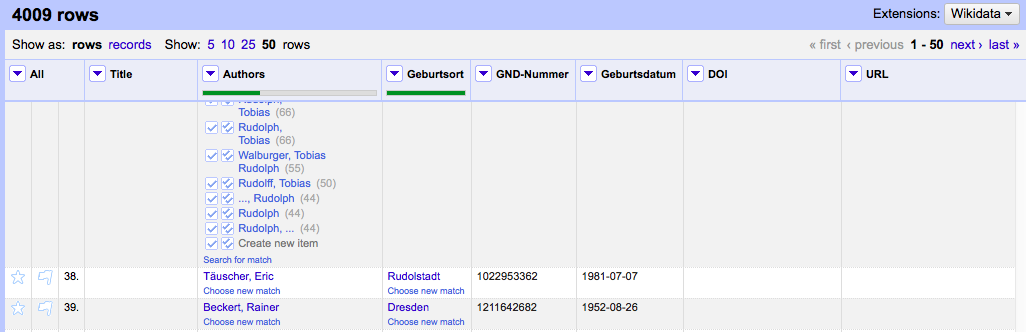
Aufgabe 2: Erweitern Sie das Template und exportieren Sie die Daten in XML.
Material: Anleitung lobig-gnd, DOAJ-Daten in OpenRefine, Vorlage aus BAIN-Unterricht vom 20.11.2020
Für diese Aufgabe bin ich von dem Template ausgegangen, das wir im Unterricht vom 20.11.2020 benutzt haben für eine Übung:
- Prefix:
<collection xmlns="http://www.loc.gov/MARC21/slim"> - Row Separator: (Zeilenumbruch)
- Suffix:
</collection> - Row Template:
<record> <leader> nab a22 uu 4500</leader> <controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield> <datafield tag="022" ind1=" " ind2=" "> <subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield> </datafield> <datafield tag="100" ind1="0" ind2=" "> <subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield> </datafield> <datafield tag="245" ind1="0" ind2="0"> <subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield> </datafield>{{ forEach(cells['Authors'].value.split('|').slice(1), v ,' <datafield tag="700" ind1="0" ind2=" "> <subfield code="a">' + v.escape('xml') + '</subfield> </datafield>') }} </record>
Ich möchte im Template wiederum die Autoren-Daten anreichern, weshalb ich die Felder 100 und 700 beachten muss. In dieser Übung soll die GND-Nummer sowie das Geburtsdatum 1:1 ergänzt werden. In der MARC21-Felddokumentation der Library of Congress schaue ich nach, welche Codes ich wie befüllen muss.
Ausgehend von dieser Formulierung im Template…
<datafield tag="100" ind1="0" ind2=" ">
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
</datafield>
…sieht so die Anreicherung mit GND-Numer und Geburtsdatum für das Feld 100 aus:
<datafield tag="100" ind1="0" ind2=" ">
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
<subfield code="0">{{cells['GND-Nummer'].value. escape('xml')}}</subfield>
<subfield code="d">{{cells['Geburtsdatum'].value. escape('xml')}}</subfield>
</datafield>
…und in der Preview in OpenRefine:
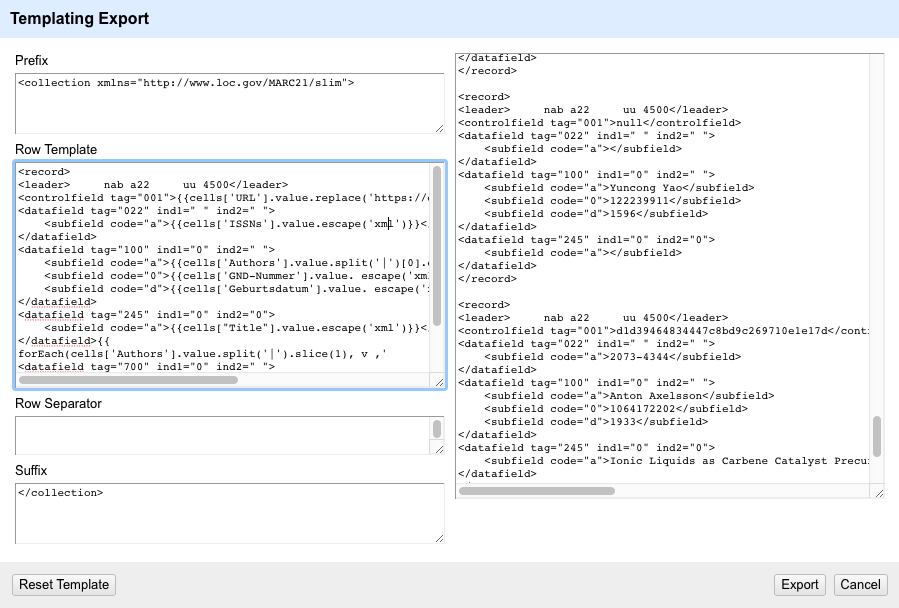
Soweit, so erfolgreich. Als ich aber dasselbe für das Feld 700 machen wollte, kam ich nicht weiter. Da die Codes sich nicht von denjenigen des Felder 100 unterscheiden, habe ich die Funktionen analog zur vorherigen formuliert:
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>
<subfield code="0">{{cells['GND-Nummer'].value. escape('xml')}}</subfield>
<subfield code="d">{{cells['Geburtsdatum'].value. escape('xml')}}</subfield>
</datafield>')
Irgendetwas scheine ich jedoch übersehen zu haben – oder ich habe einen Denkfehler gemacht – denn die Preview blieb jeweils komplett leer, sobald ich obige Zeilen eingefügt habe. Warum? Den Export als XML habe ich dennoch gemacht.
Nachtrag: Lösung für Aufgabe 2 (Feld 700)
- In den neuen Spalten muss zunächst ein Platzhalter wie z.B.
$in eine leere Zelle eingefügt werden. In dieser Erläuterung sind dies die Spalten Geburtsdatum und GND-Nummer (Abweichung von meinem Vorgehen oben):Facet>Customized Facets>Facet by blank>true.Edit cells...>Tranform>$. - Danach werden die Spalten Authors, Geburtsdatum und GND-Nummer zusammengeführt:
Edit cells>Join multi-valued cells.
Das Ergebnis könnte dann für Feld 700 so aussehen:
forEachIndex(cells['Authors'].value.split('|').slice(1), i, v ,'
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>'
+ forNonBlank(cells['GND-Nummer'].value.split('|').slice(1)[i].replace('$',''), gnd ,'
<subfield code="0">' + gnd.escape('xml') + '</subfield>', '')
+ forNonBlank(cells['Geburtsdatum'].value.split('|').slice(1)[i].replace('$',''), geburt ,'
<subfield code="d">' + geburt.escape('xml') + '</subfield>', '')
+ '</datafield>')
—
Quellen: Anleitung lobig-gnd, MARC21-Felddokumentation der Library of Congress, Vorlage aus BAIN-Unterricht vom 20.11.2020