20.11.2020 Metadaten modellieren und Schnittstellen nutzen (2/2)
Zwischenstand (Schaubild)
Das Schaubild wurde um OpenRefine erweitert:
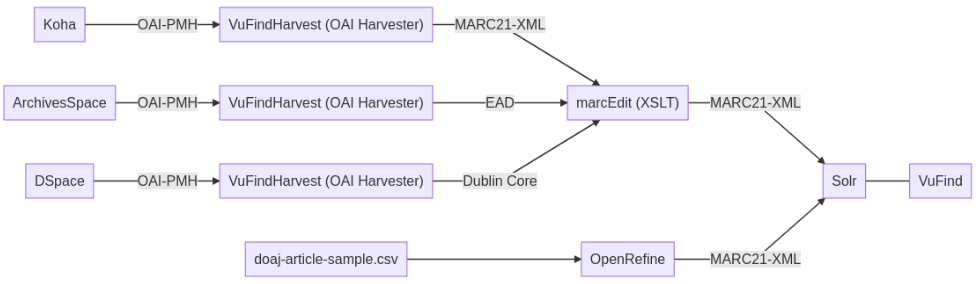
OpenRefine
OpenRefine ist ein Open-Source-Tool für die Arbeit mit unstrukturierten (“messy”) Daten. Damit lassen sich Daten analysieren, bereinigen, konvertieren und mit weiteren Daten (auch Normdaten) anreichern bzw. abgleichen. Installiert wird es i.d.R. lokal auf einem Computer und bedient über den Browser – diesen nutzt das Tool als grafische Benutzeroberfläche. Von der Optik her ähnelt es Tabellenverarbeitungssystemen wie z.B. Excel. Laut einer Umfrage des OpenRefine-Teams (2012/2018/2020) gehören zu den meistverwendeten Funktionalitäten: Normalisieren von Daten (z.B. Korrigieren von Rechtschreibefehlern), Konvertierung von Daten in ein anderes Format sowie die Vorbereitung von Daten für den Import in ein anderes System (z.B. Wikidata, Datenbank) – wobei dieser letzte Punkt nicht sehr konkret ist. Interessant ist er dennoch, wenn ich an die bevorstehende Migration von MuseumPlus Classic in ein Nachfolgesystem im Kunstmuseum Basel denke, in die ich involviert sein werde. Auch dort wird es nötig sein, die Daten im Rahmen der Vorbereitung für den Import zu bereinigen – evtl. mit OpenRefine? Eine weitere Umfrage des OpenRefine-Teams (2014/2018/2020) zeigt ausserdem, dass die Hauptanwender/innen Bibliothekar/innen sind.
Von OpenRefine unterstützte Formate
- für tabellarische Daten eignen sich besonders gut: (CSV, TSV, XLS, XLSX und auch TXT mit Trennzeichen oder festen Spaltenbreiten)
- einfaches (“flaches”) XML (z.B. MARCXML) oder JSON kann mit etwas Übung auch gut modelliert werden
- Komplexes XML mit Hierarchien (z.B. EAD) ist möglich, jedoch nur mit Zusatztools
- OpenRefine kann mit MarcEdit kombiniert genutzt werden für die Analyse und Transformation von MARC21
CSV nach MARCXML mit OpenRefine
Mit folgender Übung kommt neben EAD und Dublin Core ein weiteres Format hinzu, nämlich CSV, das wir in MARCXML konvertieren möchten. Während wir dies für die anderen beiden in MarcEdit getan haben über einen XSLT Crosswalk, migrieren wir CSV in OpenRefine. Das Vorgehen ist hier ähnlich, OpenRefine nutzt jedoch eine eigene Template-Sprache: GREL. Auch kann das Template hier direkt bearbeitet werden und steht somit nicht bereits fest wie in MarcEdit.
Damit wir auch die korrekten MARC21-Felder ansteuern und bearbeiten, nutzen wie die Feld-Dokumentation der Library of Congress. Mir kommt hier ein Praktikum, das ich vor ein paar Jahren in der Unibibliothek Basel gemacht hatte zugute, da ich sonst wohl recht Mühe hätte, mich in den Feldern, Indikatoren und Codes zurechtzufinden.
Vor der Übung lade ich mir nochmals die Beispieldaten der Library Carpentry Lesson in OpenReifne und erstelle ein neues Projekt: Create> Web Adresses (URL): https://raw.githubusercontent.com/LibraryCarpentry/lc-open-refine/gh-pages/data/doaj-article-sample.csv^
Folgende Vorlage ist ausserdem von den Dozenten bereitgestellt worden:
- Prefix:
<collection xmlns="http://www.loc.gov/MARC21/slim"> - Row Separator: (Zeilenumbruch)
- Suffix:
</collection> - Row Template:
<record> <leader> nab a22 uu 4500</leader> <controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield> <datafield tag="022" ind1=" " ind2=" "> <subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield> </datafield> <datafield tag="100" ind1="0" ind2=" "> <subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield> </datafield> <datafield tag="245" ind1="0" ind2="0"> <subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield> </datafield>{{ forEach(cells['Authors'].value.split('|').slice(1), v ,' <datafield tag="700" ind1="0" ind2=" "> <subfield code="a">' + v.escape('xml') + '</subfield> </datafield>') }} </record>
Aufgabe 1: Reverse Engineering
Beschreiben Sie anhand des Vergleichs der Ausgangsdaten mit dem Ergebnis mit ihren eigenen Worten welche Transformationen für die jeweiligen Felder durchgeführt wurden.
- leader: Keine Transformationsregel, Inhalt wird 1:1 so übertragen
- 001 – Control Number (NR): Es wird nicht mehr die ganze URL ausgegeben, sondern nur noch die ID. Der vordere Teil (URL) wird herausgeschnitten bzw. ersetzt durch “Nichts” – dies geht, weil dieser Teil bei allen gleich ist.
- 022 – International Standard Serial Number (R): Keine Transformationsregel, Inhalt wird 1:1 so übertragen
- 100 – Personal Name (NR): Mehrere Autoren werden getrennt, es bleibt nur die erstgenannte Person in diesem Feld
- 245 Title Statement (NR): Keine Transformationsregel, Inhalt wird 1:1 so übertragen
- 700 Personal Name (R): Der erste Autor wird herausgeschnitten, alle anderen Personen werden in dieses Feld übertragen
Hinweis: die Funktion value.escape('xml') sollte man überall integrieren, damit man am Schluss keine Zeichen hat, die nicht XML-konform sind. Unerlaubte Zeichen – alle ausser Unicode – werden, falls möglich, umgewandelt.
Aufgabe 2: Template ergänzen
Suchen Sie für weitere Spalten in den DOAJ-Daten die Entsprechung in MARC21. Erstellen Sie geeignete Regeln im Template, um die Daten der gewählten Spalten in MARC21 zu transformieren.
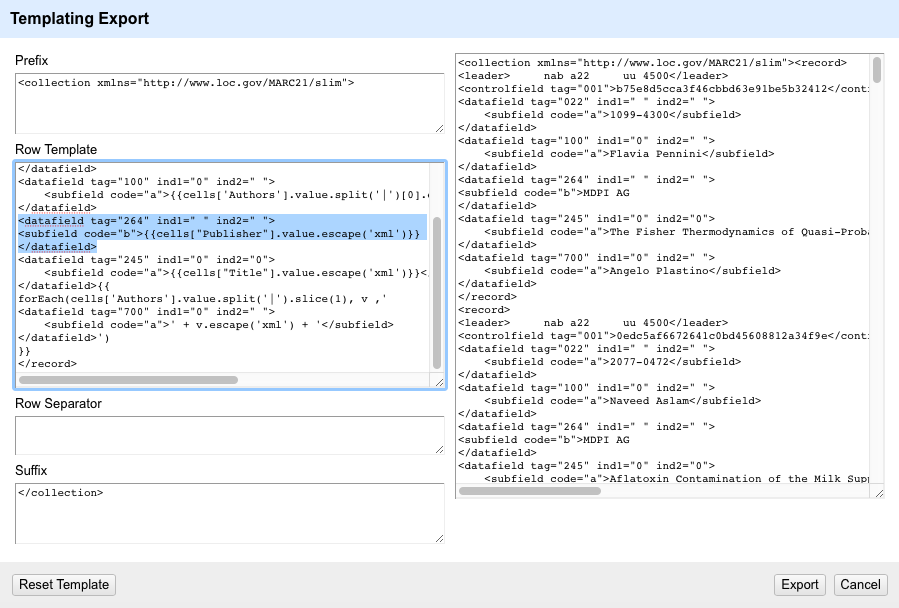
Meine Gruppe hat sich dazu entschieden, die Spalte Publisher in das Template zu integrieren. Die Entsprechung in MARC21 ist das Feld 264 mit Code $a. Wir haben dabei keine spezielle Funktion eingebaut, ausser die Escape-XML, die ja immer dabeisein sollte. Somit wird der Inhalt in der Spalte Publisher in MARCXML 1:1 übertragen:
<datafield tag="264" ind1=" " ind2=" ">
<subfield code="b">{{cells["Publisher"].value.escape('xml')}}
</datafield>
In der Preview in OpenRefine sieht das dann so aus (blau markiert):
Quellen: OpenRefine, Feld-Dokumentation der Library of Congress, BAIN-Skript 5