30.10.2020 Metadaten modellieren und Schnittstellen nutzen (1/2)
Zwischenstand (Schaubild)
Wo stehen wir momentan? Im Kurs haben wir die drei Systeme Koha, ArchivesSpace und DSpace kennengelernt. Auch haben wir uns angeschaut, welche Schnittstellen diese Systeme anbieten und in welchen Metadaten-Formaten die dort vorhandenen Daten exportiert werden können. In der heutigen Unterrichtseinheit haben wir über die OAI-PMH-Schnittstelle, die bei allen dreien unterstützt wird, über einen OAI-Harvester (VuFindHarvest) Metadaten eingesammelt. Bei Koha im Format MARC21-XML, bei ArchivesSpace in EAD und bei DSpace in Dublin Core (hier gäbe es weitere Möglichkeiten aber wir wählen das weit verbreitete DC). Mit MarcEdit führen wir anschliessend einen XSLT Crosswalk durch, sodass wir nicht mehr unterschiediche Metadatenformate haben, sondern nur noch MARC21-XML. Mit MarcEdit hönnte man OAI-PMH eigentlich auch direkt harvesten – für den Lerneffekt nehmen wir aber einen Umweg und nutzen verschiedene Tools. Am Ende des Kurses laden wir diese MARC21-XML-Daten in ein Discoverysystem. Wie nutzen hierfür VuFind, welches die Technologie Solr verwendet.
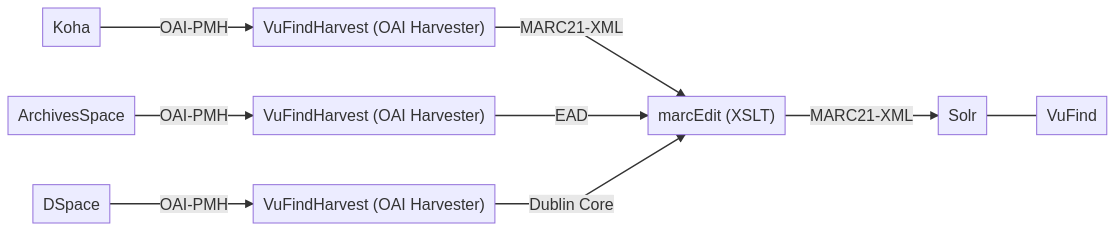
- VuFindHarvest: Die Open-Source-Software VuFindHarvest ist Teil des VuFind-Projects aber kann auch als stand-alone Tool verwendet werden. Damit lassen sich Metadaten aus einem System rausholen über eine OAI-PMH-Schnittstelle.
- MarcEdit: Kostenlose Software (nicht Open Source) und meistgenutztes Zusatztool für die Arbeit mit MARC21. MarcEdit wurde 1999 von Terry Reese entwickelt – ursprünglich für ein umfassendes Datenbank-Projekt der Oregon State University.
- VuFind: Die freie Software VuFind ist ein bibliothekarisches Suchsystem, das an der Villanova University (USA) entwickelt wurde und international häufig eingesetzt wird. Ermöglicht werden Grundfunktionalitäten eines Discoverysystems wie Facettensuche, erweiterte Suche, Anzeige von ähnlichen Titeln, Verschlagwortung oder das Kennzeichnen als Favorit.
- Solr: Solr ist die “eigentliche Suchmaschine” hinter VuFind und bietet leistungsstarke Suchfunktionalitäten an. Funktionen sind etwa Highlighting von Suchergebnissen, Rechtschreibevorschläge oder Verfeinerung von Suchergebnissen. Eine Alternative zu Solr stellt Elasticsearch dar.
Metadaten modellieren und Schnittstellen nutzen
Schnittstellen SRU, OAI-PMH, Z39.50
Im Bibliotheks- und Archivbereich gibt es einige Übertragungsprotokolle, wovon drei weit verbreitet sind: Z39.50, SRU (Search/Retrieve via URL) sowie OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting). Die ersten beiden gehen auf die Library of Congress zurück, Letztere auf die Open Archives Initiative. Obwohl Z39.50 schon sehr alt ist, ist sie noch immer im Einsatz. Nachteil ihres Alters ist jedoch, dass es zur Verwendung zusätzliche Software braucht. Im Gegensatz dazu kennen die beiden jüngeren SRU und OAI-PMH die Internetstandards, sodass Anfragen in Form von URL zusammengestellt werden könen und sie direkt über den Browser abrufbar sind (keine Zusatzsoftware nötig). Z39.50 und SRU kommen v.a. bei Live-Abfragen und gezieltem Datenabruf mit vielen Parametern zum Einsatz, während sich OAI-PMH v.a. für grössere Datenabzüge und regelmässige Aktualisierungen eignet.
Metadaten über OAI-PMH harvesten mit VuFindHarvest
Bereits vorher haben wir Daten aus den bekannten Systemen über das User Interface exportiert (im Admin-Bereich). Mit Nutzung von öffentlichen Schnittstellen kommt man nun auch an Daten heran, auf die man über die Benutzeroberfläche keinen Zugriff hat. Mit VuFindHarvest kann man Daten “ernten” (harvesten), welche in den Systemen über die Schnittstelle OAI-PMH zugänglich gemacht werden. Hierfür muss man zunächst prüfen, ob die OAI-PMH-Endpoints in Koha, ArchivesSpace ud DSpace überhaupt verfügbar sind (dies haben die Dozenten für uns übernommen). Anschliessend werden die Daten mit dem Tool abgerufen und als XML auf der Festplatte gespeichert. Wichtig für das Harvesting ist es, die genaue Bezeichnung der Metadatenformate zu kennen: Bei Koha lautet diese marcxml, bei ArchivesSpace oai_ead und bei DSpace oai_dc.
Installation der Software VuFindHarvest, die in PHP geschrieben ist. Composer (Paketverwaltung für PHP) wird für die Installation empfohlen:
sudo apt update
sudo apt install composer php php-xml
cd ~
wget https://github.com/vufind-org/vufindharvest/archive/v4.0.1.zip
unzip v4.0.1.zip
cd vufindharvest-4.0.1
composer install
Übung: Harvesting
Mit dem Harvesting habe ich mich zunächst etwas schwer getan, weil ich die Shell noch immer als nicht-intuitives, unberechenbares Ding wahrnehme. Auch kam es mir so vor, als wäre das Tempo heute höher und die Anleitungen dürftiger als bisher. Leider bin ich für die Übung zudem ich einer eher “schwachen” Gruppe gelandet, sodass wir uns auch nicht gegenseitig helfen konnten. Glücklicherweise hatten wir direkt nach der Übung eine Pause, in der sich Herr Lohmeier Zeit genommen hat, mir ausführlich die Übung zu erläutern (danke!). Dies hat extrem geholfen, sodass auch ich die Daten rechtzeitig für die nächste Aufgabe (XSLT Crosswalk) parat hatte. Grundsätzlich benötigt VuFindHarvest drei Parameter: die URL, das Format sowie das Verzeichnis (wohin gespeichert werden soll). Konkret lauten die Kommandos für die drei Systeme:
Koha:
cd ~/vufindharvest-4.0.1
php bin/harvest_oai.php --url=http://example.com/oai_server --metadataPrefix=oai_dc koha
ArchivesSpace:
cd ~/vufindharvest-4.0.1
php bin/harvest_oai.php --url=http://localhost:8082 --metadataPrefix=oai_ead archivesspace
DSpace:
cd ~/vufindharvest-4.0.1
php bin/harvest_oai.php --url=http://demo.dspace.org/oai/request --metadataPrefix=oai_dc --set=com_10673_1 dspace
XSLT Crosswalks mit MarcEdit
In einem weiteren Schritt haben wir die Daten, welche aus Koha (MARC21-XML), ArchivesSpace (EAD) und DSpace (Dublin Core) geharvest worden sind, vereinheitlicht, sodass alle in MARC21-XML vorliegen. Dieser Schritt war wohlbemerkt für Koha nicht nötig. Die Konvertierung der Daten erfolgte mit dem Tool MarcEdit über einen XSLT Crosswalk: “Crosswalk” bezeichnet die Umwandlung von einem Metadatenstandard in einen anderen. Dieser beruht auf Regeln – dem sog. “Mapping” – die festlegen, wie Elemente und Regeln zugeordnet werden müssen. Idealerweise wird eine 1:1-Zuordnung (verlustfrei) angestrebt aber dies ist meistens nicht möglich, sodass mit Informationsverlust gerechnet werden muss. XSLT bildet die Programmiersprache zur Transformation von XML-Dokumenten.
Übung: XSLT Crosswalks anwenden
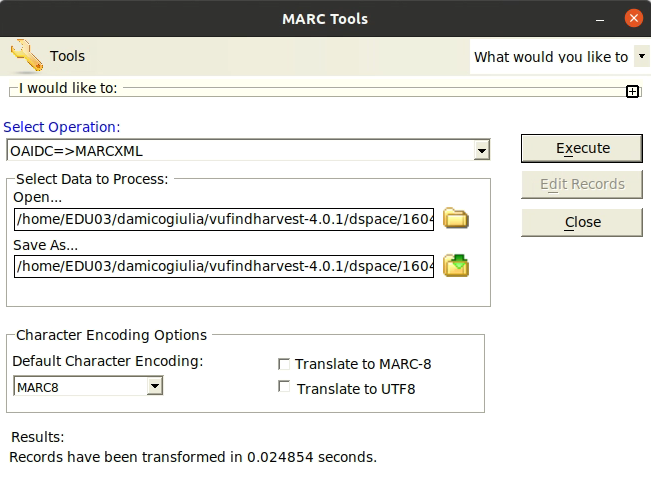
Nach der Installation von MarcEdit sowie dessen Konfiguration für Linux konnte die Transformation beginnen. Das Tool ist nicht sehr benutzerfreundlich, sodass meine Gruppe mehrmals Hilfe holen musste. Bei der zweiten Konvertierung hatten wir den Dreh aber raus und konnten den Auftrag sauber abschliessen. Die Umwandlung von Dublin Core (aus DSpace) in MARC21-XML sah in MarcEdit so aus:
Quellen: VuFindHarvest, MarcEdit, VuFind, Solr, BAIN-Skript 5